بهینهسازی عملکرد Eloquent در ایجاد و آپدیت از روی فایل csv
برای درونریزی (import) فایلهای csv و یا منابع دیگر در لاراول ابتدا باید تمام رکوردهای فایل را با پایگاه داده چک کنیم که رکورد موردنظر وجود دارد یا خیر. اگر رکورد وجود داشت ستونهایش براساس داده جدید بروزآوری شوند و اگر رکورد وجود نداشت، رکورد جدید ایجاد شود. روشهای زیادی برای توسعه چنین سناریویی وجود دارد که در زیر بررسی خواهیم کرد. برخی از این روشها از نظر عملکرد بهینه هستند و فشار کمتری روی سرور وارد میکنند یا سرعت پاسخگویی بالاتری دارند.

در ادامه این نوشته مطالب زیر ارائه شده اند :
- روش عمومی غیر بهینه
- بهینه سازی اول: خوانایی بهتر با تابع ()updateOrCreate
- بهینه سازی دوم: یک کوئری با Upsert
- بهینهسازی سوم: منع درخواستهای پایگاهداده با collections
- بهینهسازی چهارم: ترکیب چند ()create با ()insert
- بهینهسازی پنجم: استفاده از ()chunk در درونریزی بزرگ
- بهینهسازیهای بیشتر ؟
روش عمومی غیر بهینه
فرض کنید فایل csv که شامل +1000 اکانت کاربری است را میخواهیم وارد پایگاهداده بکنیم:
آرایه accountsArrayFromCSV$ که ستونهای 0 آن شماره اکانت و ستون 1 آن مبلغ موجودی اکانت است.
array (
0 =>
array (
0 => '610768',
1 => '630',
),
1 =>
array (
0 => '773179',
1 => '403',
),
2 =>
array (
0 => '346113',
1 => '512',
),
// ...
);
برای درون ریزی این فایل کد زیر را در نظر بگیرید :
foreach ($accountsArrayFromCSV as $row) {
$account = Account::where('number', $row[0])->first();
if ($account) {
$account->update(['balance' => $row[1]]);
} else {
Account::create([
'number' => $row[0],
'balance' => $row[1]
]);
}
}
کد بالا دقیقا سناریوی گفته شده در اول نوشته را انجام خواهد داد. ابتدا چک خواهد کرد که رکورد داخل پایگاه داده هست یا نه سپس اقدام به ایجاد یا آپدیت خواهد کرد.
امادو تا مشکل وجود دارد:
- کد کمی طولانی است و خوانایی کمتری دارد و میتوانیم با امکانات لاراول آن را کوتاه کنیم.
- کد باعث فراخوانی درخواستهای زیادی از پایگاه داده میشود - 1 یا 2 درخواست برای هر ردیف.
به کمک پکیج Laravel Debugbar میتوانیم خروجی درخواستهای SQL را ببینیم :
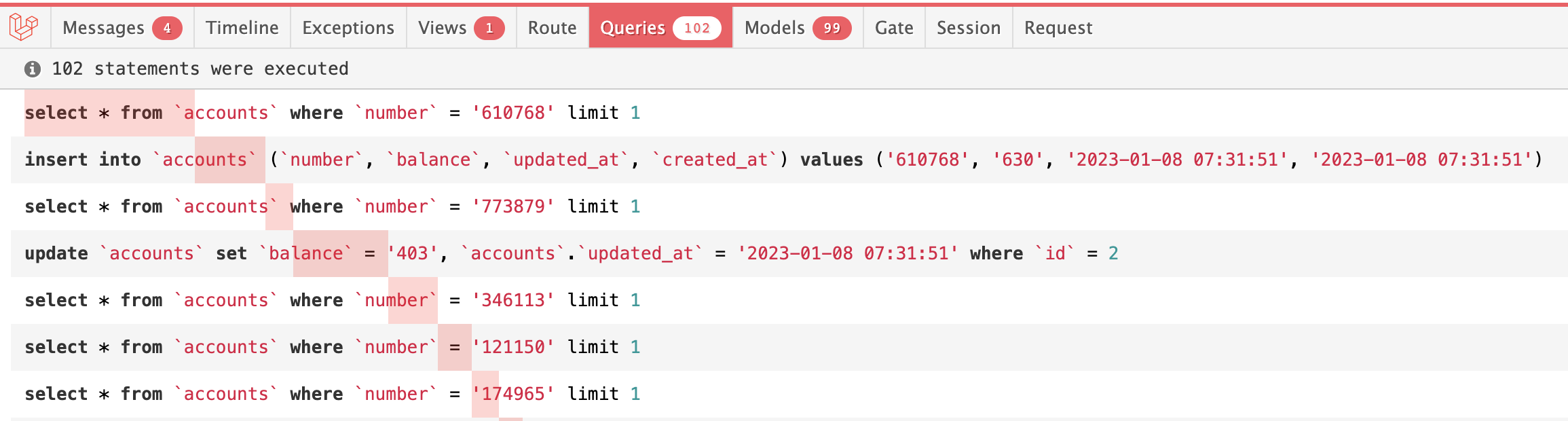
در این مثال ما 100 اکانت داخل پایگاه داده داریم تا هردو حالت ایجاد و آپدیت را شبیهسازی کنیم. در این مثال 100 رکورد آپدیت شده و 900 رکورد ایجاد میشود.
اگر به تصویر خروجی دقت کنید برای هر رکورد دستور select اجرا میشود و یک درخواست برای ایجاد و یا آپدیت فراخوانی میشود.
پس با این روش ما حداقل 100 درخواست اضافی روی مثال بالا خواهیم داشت. اگر تعداد ردیفهای فایل csv افزایش یابد یا رکوردهای تکراری زیاد شود چه باید بکنیم ؟
در زیر روشهای بهینه را یاد خواهیم گرفت.
بهینه سازی اول: خوانایی بهتر با تابع ()updateOrCreate
کد مشابهی با استفاده از تابع پرکاربرد ()updateOrCreate به وسیله Eloquent میتوانیم بنویسیم.
foreach ($accountsArrayFromCSV as $row) {
Account::updateOrCreate(
['number' => $row[0]], // key to search by
['balance' => $row[1]] // update the value
);
}
این تابع به وسیله دو آرایه مجزا عمل آپدیت یا ایجاد را مدیریت میکند. در آرایه اول ستونهایی قرار میگیرد که به وسیله ()where چک میشود که ردیف در پایگاه داده هست یا نه . در آرایه دوم هم ستونهایی هستند که با آرایه اول merge شده و اگر ردیف تکراری بود آپدیت روی ستونهای آرایه دوم صورت میگیرد. اگر تکراری نبود ردیف جدید با مجموع ستونهای آرایه اول و دوم ایجاد میشود.
به طور کلی این بهینه سازی فقط برای خوانایی بهتر کد و کوتاه شدن اندازه کد میباشد و همچنان مشابه کد اصلی مشکل 2 درخواست برای هرردیف پا برجا هست.
بهینه سازی دوم: یک کوئری با Upsert
از لاراول نسخه 8 تابع ()upsert معرفی شد که به وسیله آن تمام کوئریهای SQL ترکیب شده و یک درخواست به پایگاهداده ارسال میشود. با این تابع دیگر نیازی به استفاده از foreach نخواهد بود.
برای این منظور نیاز هست که ستونهای فایل csv کلیدهایی همنام با ستونهای پایگاهداده داشته باشند.
array (
0 =>
array (
'number' => '610768',
'balance' => '630',
),
1 =>
array (
'number' => '773179',
'balance' => '403',
),
2 =>
array (
'number' => '346113',
'balance' => '512',
),
// ...
);
در نهایت برای درون ریزی از کد زیر استفاده میکنیم.
Account::upsert($accountsArrayFromCSV, ['number'], ['balance']);
تابع ()upsert سه ورودی میگیرد. که در زیر توضیح داده شده است:
- ورودی اول آرایهای از ردیفها که از فایل csv خوانده میشود.
- ورودی دوم آرایهای از کلیدهای منحصربه فرد (unique) هستند که ردیفهای متناظر را روی پایگاهداده شناسایی میکنند.
- ورودی سوم نیز آرایهای از مقادیری هستند که اگر ردیف متناظر وجود داشت آپدیت شوند.
خروجی کوئری SQL به شکل زیر خواهد بود :
insert into `accounts` (`balance`, `created_at`, `number`, `updated_at`)
values ('630', '2023-01-08 07:52:23', '610768', '2023-01-08 07:52:23'),
('403', '2023-01-08 07:52:23', '773179', '2023-01-08 07:52:23'),
// ...
('828', '2023-01-08 07:52:23', '935461', '2023-01-08 07:52:23')
on duplicate key
update `balance` = values(`balance`), `updated_at` = values(`updated_at`);
یک درخواست به پایگاه داده ایجاد میشود و سرعت بالاتری دارد ولی صبر کنید!
در اغلب موارد نتایج حاصل از این کوئری اشتباه خواهد بود. چون مشکل عدم شناسایی حالت on duplicate key پیش میآید. به عبارت ساده کلیدهای تکراری بوجود میآیند.
یکی از معایب و ضعفهای تابع ()upsert محدودیت آن در درایورهای پایگاهداده است. در داکیومنت لاراول آمده است :
All databases except SQL Server require the columns in the second argument of the upsert method to have a "primary" or "unique" index. In addition, the MySQL database driver ignores the second argument of the upsert method and always uses the "primary" and "unique" indexes of the table to detect existing records.
تمام پایگاهدادهها به جز SQL Server ورودی دوم را برای چک کردن کلیدهای "unique" یا "primary" نیاز دارند. یک استثنا نیز وجود دارد آن هم درایور MySQL است که ورودی دوم را به کلی نادیده میگیرد و کلیدهای اصلی خود پایگاهداده را مدنظر میگیرد که به صورت پیشفرض ID است.
زمانی میتوانیم مطمئن باشیم که خروجی این تابع صحیح خواهد بود که در لایه پایگاهداده ستون number حتما از نوع unique باشد.
اگر ما این شرط را قرار دهیم که ستون کلید در لایه پایگاهداده تعریف شده است این تابع بسیار در عملکرد کد ما تاثیر مثبت خواهد گذاشت.
بهینهسازی سوم: منع درخواستهای پایگاهداده با collections
در مواقعی که از تابع ()upsert به دلیل ساختار پایگاهداده نمیتوانیم استفاده کنیم، بهتر است از حلقه foreach و جایگزینی memory به جای کوئریهای پایگاهداده استفاده کنیم.
در ابتدا کل اکانتهای کاربری موجود در پایگاهداده را دریافت کرده به صورت آرایه یا مجموعه (collection) ذخیره میکنیم و سپس روی این مجموعه چک میکنیم که رکورد موجود هست یا نه.
$accounts = Account::pluck('balance', 'number');
// This becomes the array of key-value pairs, number => balance
foreach ($accountsArrayFromCSV as $row) {
if (isset($accounts[$row[0]])) {
if ($accounts[$row[0]] != $row[1]) {
// We launch update only if the value changed
Account::where('number', $row[0])->update(['balance' => $row[1]]);
}
} else {
Account::create([
'number' => $row[0],
'balance' => $row[1]
]);
}
}
همینطور که میبینید یک کوئری برای دریافت ردیفها ارسال میشود و مقدار accounts$ به وسیله مقادیر موجود در فایل csv بررسی میشوند.
در مثال ساده این نوشته، به دلیل اینکه برای کلید number یک مقدار balance وجود دارد از تابع ()pluck استفاده شده است که ورودی اول، کلید ورودی دوم خواهد بود.
در پروژههای پیچیدهتر کلید متناظر برای یک ستون نیست و چند ستون دارد، به همین خاطر در collection از تابع ()keyBy<- استفاده میکنیم.
برای نمونه اگر ستونهای balance و verified_at را داشته باشیم:
$accounts = Account::all()->keyBy('number');
foreach ($accountsArrayFromCSV as $row) {
if (isset($accounts[$row[0]])) {
$account = $accounts[$row[0]];
if ($account->balance != $row[1] || $account->verified_at != $row[1]) {
Account::where('number', $row[0])->update([
'balance' => $row[1],
'verified_at' => $row[2],
]);
}
} else {
Account::create([
'number' => $row[0],
'balance' => $row[1],
'verified_at' => $row[2],
]);
}
}
در نتیجه، تعداد کمتری درخواست به پایگاهداده خواهیم داشت.
اگر رکوردهای جدید برای ایجاد یا آپدیت نداشته باشیم صرفا یک کوئری به پایگاهداده ارسال میشود و اگر رکوردهای جدید برای ایجاد یا آپدیت داشته باشیم برای هر ردیف یک کوئری فراخوانی میشود.
بهینهسازی چهارم: ترکیب چند ()create با ()insert
کدی که در حال بررسی آن هستیم دو بخش اصلی دارد: بخش ایجاد ردیف و بخش آپدیت ردیف موجود. حال بیایید به بخش ایجاد نگاه کنیم:
foreach ($accountsArrayFromCSV as $row) {
if (record_exists()) {
// ...
} else {
Account::create([
'number' => $row[0],
'balance' => $row[1]
]);
}
}
اگر ما 100 رکورد جدید داشته باشیم همچنان برای هر رکورد یک کوئری به پایگاهداده ارسال میشود.
آیا میتوانیم راهی پیدا کنیم که تمام این 100 رکورد به صورت یکجا در پایگاهداده ایجاد شوند؟
بله اگر تابع ()create را با تابع ()insert که ورودیاش میتواند آرایهای از رکوردها باشد، جایگزین کنیم.
در حقیقت به جای اینکه هربار که حلقه اجرا میشود درخواست جدیدی به پایگاهداده ارسال کنیم کافی است تمام آن رکوردها را در یک آرایه ذخیره کنیم و در انتهای حلقه آن را یکجا به پایگاهداده ارسال کنیم.
$accounts = Account::pluck('balance', 'number');
$newAccounts = [];
foreach ($accountsArrayFromCSV as $row) {
if (isset($accounts[$row[0]])) {
// ... update
} else {
$newAccounts[] = [
'number' => $row[0],
'balance' => $row[1]
];
}
}
if (count($newAccounts) > 0) {
Account::insert($newAccounts);
}
در نتیجه ما کلا 2 کوئری پایگاهداده خواهیم داشت. یکی مقادیر همه اکانتهای کاربری را دریافت میکند و دیگری ایجاد یکجای رکوردهای جدید.
insert into `accounts` (`balance`, `number`)
values ('630', '610068'), ('403', '773279'), ('837', '121050');
به نظر میرسد بهترین و سریع ترین راهحل را پیدا کردیم؟ اما واقعا سریع نیست!
اگر از تابع ()insert در مدل استفاده کنیم باید محدودیتهای آن را به خاطر بسپاریم. تابعی از Query Builder هست و نه تابعی از مدل Eloquent، بنابراین هیچ یک از ویژگیهای Eloquent را نخواهد داشت. چند نمونه از این ویژگیها در زیر آورده شده است:
- پرکردن اتوماتیک created_at/updated_at
- Accessors/mutators
- Observers
- Events/listeners
- Traits
تابع ()insert به طور کلی یک درخواست به پایگاهداده است و نه بیشتر. شبیه یک کوئری خام SQL.
همچنین میتوانیم هرستونی را به صورت دستی داخل آرایه پرکنیم:
$newAccounts[] = [
'number' => $row[0],
'balance' => $row[1],
'created_at' => now()->toDateTimeString(),
'updated_at' => now()->toDateTimeString(),
];
اما اگر منطق پیچیدهای داخل Eloquent ها دارید که با هربار ایجاد رکورد جدید عملیات متعددی در پشت صحنه انجام میگیرد در این صورت تابع ()insert برای پروژه شما مناسب نخواهد بود.
بهینهسازی پنجم: استفاده از ()chunk در درونریزی بزرگ
سوال : آیا به این فکر کردید که اگر 100,000 رکورد را به ()Account::insert ارسال کنیم چه اتفاقی رخ میدهد؟
کمی که مکث کنید منظور از این سوال را خوب خواهید فهمید. درست است در لایه پایگاهداده با خطا مواجه خواهیم شد. در تعداد رکوردهای ارسالشده به یک کوئری SQL محدودیت وجود دارد بنابراین خطایی مشابه "Prepared statement contains too many placeholders" دریافت خواهیم کرد.
برای اینکه بتوانیم از این ویژگی روی دادههای بسیار بزرگ بهرهمند شویم باید آرایه داده را به چند آرایه کوچکتر تقسیم کنیم که به قسمتها "chunks" میگویند و هر یک از این قسمتها را در یک درخواست SQL مجزا ارسال کنیم.
به مثال زیر دقت کنید:
if (count($newAccounts) > 0) {
foreach (array_chunk($newAccounts, 1000) as $chunk) {
Account::insert($chunk);
}
}
در مثال بالا آرایه به 1000 قسمت مساوی تقسیم شده است. عدد بدست آمده براساس مقادیر داخل آرایه، ستونهای موجود و همچنین قدرت سرور تقسیم شده است. برای هرپروژهای متناسب با شرایط میتوان عددهای دیگری را آزمود.
بهینهسازیهای بیشتر ؟
یکی از موضوعات مهم که در این نوشته به آن پرداخته نشد، اندازه و بزرگی آرایههای زبانبرنامه نویسی PHP است که به صورت متغیر در RAM دستگاه ذخیره میشود. البته این موضوع به یک نوشته مجزا نیاز دارد تا به صورت مفصل محدودیتها و راهکارهای رهایی از این محدودیت در آن گنجانده شود.
حتما به یاد داشته باشیم که از متغیرهای آرایه موقت استفاده نکنیم و همچنین عملکرد هربخش از کد را مجزا بررسی و عیبیابی کنیم.
در آینده نوشتههای متعددی برای بهینهسازی عملکرد در سطح پیشرفته ارائه خواهند شد که مناسب دادههای بزرگ میباشند. اگر شما به چنین بهینهسازیهایی نیاز دارید حتما مترووب را دنبال کنید 😉

علی مهدوی برنامه نویس ارشد وب